原创文章,如需转载,请注明来自:https://bigzuo.github.io/
关键词:Full GC、Stop the world、request delay
背景介绍
最近公司新上线的一个长连接推送系统,在推送消息量增大时会出现频繁 Full GC, 应用响应也开始变慢。考虑这可能是一个典型的异常 Full GC 问题,所以就记录下整个问题排查过程,以便事后参考。
排查思路
分析已有 GC 日志
针对任何 GC 问题,第一件事就应该是查看线上 GC 日志,从 GC 日志中发现异常和突破口。
在分析已有 GC 日志时,发现每次 Full GC 时,老年代回收的内存空间非常少,或者几乎不回收,找到问题切入点。
通过分析年轻代回收日志可以得知:老年代对象空间占用为:1398015K(堆整体使用空间) - 69888K(年轻代使用空间)=1328127K,约1297M;
通过分析老年代
CMS Final Remark阶段日志可以得知:老年代对象在 Full GC 后空间占用为:1328127K,约 1297M;和 Full GC 前一样;所以频繁 Full GC 的原因是因为老年代对象存活时间长、无法被有效回收,造成每次都空间不够,但是每次 Full GC 又释放不了空间,触发频繁 Full GC 恶性循环;
1 | 2020-08-17T14:17:20.687+0800: 15966.728: [GC (Allocation Failure) 2020-08-17T14:17:20.687+0800: 15966.728: [ParNew: 629120K->69888K(629120K), 0.4434747 secs] 1868694K->1398015K(2027264K), 0.4438074 secs] [Times: user=0.72 sys=0.13, real=0.44 secs] |
复现问题验证猜测
单次通过 GC 日志分析的结论可能具有偶然性,不一定能精确定位问题。所以为了验证猜测,我们使用jstat命令实时查看 JVM 的垃圾回收状态,看看是否每次 Full GC 的现象和刚才分析的一致。
我们在相同的环境,重新模拟了批量消息发送的场景。在消息发送期间,通过jstat命令发现,每次 Full GC 几乎都不能有效回收内存空间。如下显示:
在 16s 之内,应用触发了 7 次 Full GC ,但是老年代的空间占用率一直在 95.5%左右,基本上没有波动,说明问题原因在于老年代里面的对象无法被回收掉,和猜测一致。
1 | [root@DockerHost applogs]# /wls/jdk1.8.0_131/bin/jstat -gcutil $pid 1000 |
既然是内存无法回收引起的问题,那就 Dump 出内存堆栈,找出是哪些对象回收不掉、为什么回收不掉。
内存堆栈分析
使用 jmap 命令 Dump 内存堆栈:
1 | [root@DockerHost applogs]# /wls/jdk1.8.0_131/bin/jmap -dump:format=b,file=heapInfo.hprof $pid |
下载 dump 文件,使用 JDK 自带工具 visualvm 分析内存堆栈:
- 找到内存占用最大的对象类型。如图可见,
char[]是内存中占用空间最大的对象类型,共计有 496M,占用了 22.1% 的堆空间。
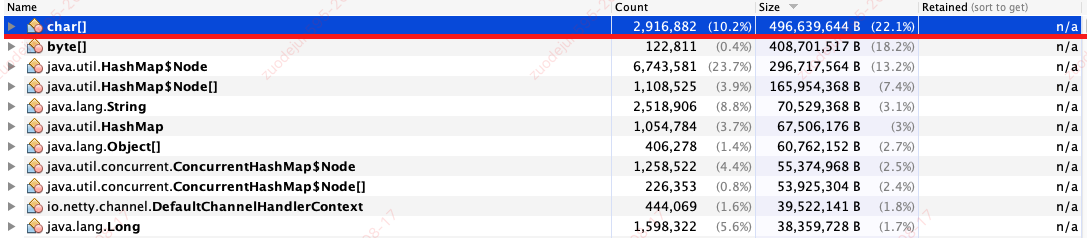
- 在内存占用最大的对象类型中查找可疑对象。一般情况下,可疑对象很多,有可能需要输出多次内存堆栈、多次查找对比,才能定位问题对象。根据经验,一般出现大量相同对象,很有可能就是我们要找的问题对象。
分析内存对象时,发现如下大量相同对象,且每个对象为 35k,明显属于超大对象,正常业务对象一般较小;很有可能它就是本次问题的元凶。
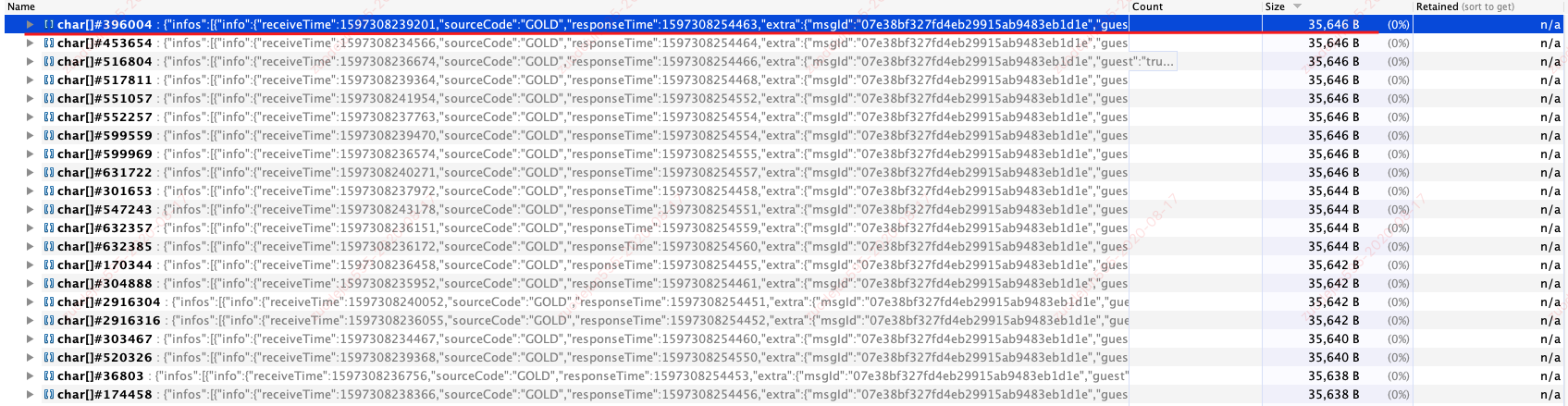
- 利用
visualvm深入分析该对象的内容。通过对象的引用关系,发现这个对象和公司内部的一个监控埋点数据收集系统的 SDK 有关。

从问题对象找到问题代码
根据引用关系查找问题代码。通过排查代码,发现如下可疑操作:长连接推送系统为了记录会话状态、用户在线信息等数据,会将相关数据暂存到 LinkedBlockingQueue 队列中,然后再异步发送到监控采集系统的 kafka 集群。LinkedBlockingQueue长度默认是 1w, 测试环境实际配置是 50w. 根据内存堆栈显示,一个相关对象为 35k, LinkedBlockingQueue存储1w 个这种对象,就会占用约 350M 内存。这些内容如果不能被及时消费,会一直存在于内存,无法被 GC 回收掉,进而会触发频繁 full gc,理论分析和实际 GC 现象一致。
问题代码:
1 | BlockingQueue 长度默认是 1w,测试环境实际配置 50w.private void traceSession(SocketUser socketUser, Date connectTime, Response response,long middleTime1, long middleTime2) { |
结合 Full gc 期间的应用日志,发现应用日志也在频繁报相关异常:LinkedBlockingQueue 队列已满,无法继续添加。这个日志也侧面证明,LinkedBlockingQueue关联的对象都还一直在内存中,导致内存无法被有效回收。
1 | 2020-08-13 17:15:05.387 ERROR 462 --- [nioEventLoopGroup-3-66] c.paic.smp.conn.pool.trace.TraceService : Metric SEND_MESSAGE Event TEMP_GROUP_MSG Trace Error {} |
至此,基本可以确定频繁 Full GC 的问题和这段代码有关。
临时验证方案
找到原因后,通过把LinkedBlockingQueue 队列长度调小、或者关闭相关功能,都应该可以避免问题再次出现,并验证猜测是否合理。因此,我们针对如下两个场景做了相关验证,发现问题再未出现,GC 也恢复正常,Full GC 很少出现,并且每次 Full GC 时都能够有效回收资源。
- 把
LinkedBlockingQueue队列长度调小(由 1w 改成 100) - 关闭
LinkedBlockingQueue采集功能
定位结论
- 长连接组件为了统计在线用户信息、发送状态等数据,应用中使用了一个
LinkedBlockingQueue队列暂存相关数据,然后再异步发送到监控采集系统的 kafka 集群; LinkedBlockingQueue队列长度默认是 1w, 测试环境实际配置是 50w。队列保存的对象每个大小约为 35k,假如存储 1w 个类似对象,所需内存约为 350M;- 在进行大量消息发送时,
LinkedBlockingQueue队列中对象积压,又因为队列长度配置过大,导致大量对象驻留在内存中,导致内存空间不足,触发 Full GC。 - 因队列长度过大、对象在队列中存活时间较长,所以每次 Full GC 都无法有效 GC 并释放空间,进而导致更加频繁 Full GC。频繁 Full GC 又触发系统停顿增加、资源消耗增多,因此导致性能下降;
优化建议
根据一般 Metric 数据收集策略,我觉得可以从如下两个方向优化,但是由于不太了解长连接平台的具体实现细节,具体优化方案可能需要具体分析。
- 客户端聚合:在线用户状态、会话数据等信息一般只关注最终统计值,实际每个 Metric 的数据明细可能并不重要,所以采集的 Metric 数据可以按批在客户端聚合,只将聚合后信息发送到 Kafka 集群,这样可以大幅减少待发送数据、提高信息发送效率;
- 控制采样率:大部分场景并不要求采集数据 100% 准确,所以可以通过控制采样率,减少源头数据的采集,来减少数据的存储、发送的资源消耗,同时提高效率;