原创文章,如需转载,请注明来自:https://bigzuo.github.io/
背景介绍
项目开发过程中经常会需要生成一个唯一ID,并且由于现在项目应用都是集群部署,所以更多时候还需要保证唯一ID支持分布式。
一些情况下,开发人员为了省事,会直接使用时间戳System.currentTimeMillis()
或者是UUID。这两种方式都存在不完善的地方。尤其是采用时间戳,时间戳本质是毫秒数,完全不支持分布式,会存在很高可能导致生成的ID重复。UUID虽然本身生成机制可以保证全球唯一,横向扩展性好,但是部分场景下,UUID长度可能过长,并且UUID是字符串类型,对需要对ID进行排序、对比的场景支持的并不友好,索引效率也很低。
鉴于以上原因,我们基于Twitter 开源的分布式ID生成算法Snowflake重写了一套分布式ID生成算法,即可以保证分布式唯一,又可以解决采用时间戳或者UUID带来的问题。
算法详解
Snowflake是Twitter 开源的一个分布式ID生成算法,目前使用范围很广。其核心思想是将一个long类型的数字分成4段,其中毫秒内自增序列占12位,机器ID占5位,机房ID占5位,时间戳占41位,最高位为符号位,然后组合生成一个64位long类型的分布式唯一ID。ID长度不超过18位,并且长时间内趋势递增,方便分析、统计和排序。这个算法理论上可以保证在69年内、1024台机器上生成的ID唯一。
我们结合项目组的实际情况,即一般一个应用部署的机器集群不会超过100台,并且一般都部署在同一机房,做了如下改造: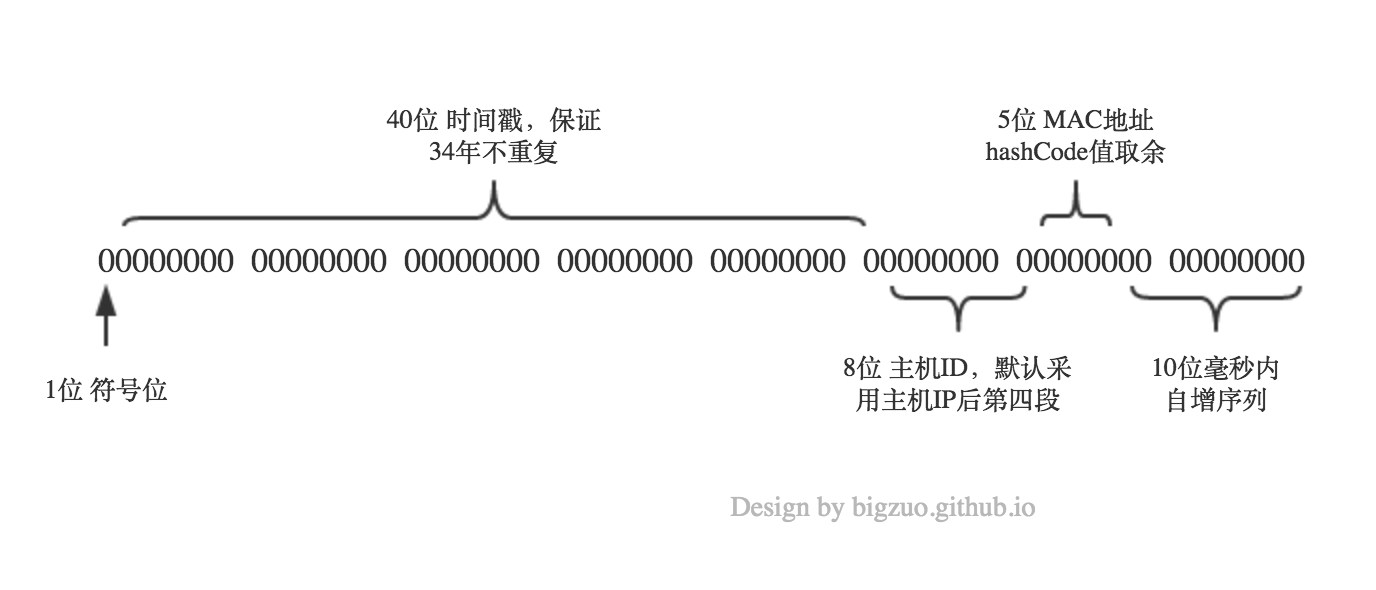
- ID生成规则重组。毫秒内自增序列占10位,机器ID占8位,默认采用服务器IP的第四段,机器MAC地址hoshCode占5位,时间戳占40位(见上图)。这样就可以保证在同一机房、同一网段的256台机器生成的ID唯一。
- 新增一个ID生成算法:
uniqueIdCurDay(),可以生成一天内不重复的分布式唯一ID,并且长度不超过14位。因为在和关联系统交互中,经常关联方会要求生成一个一天内不重复的ID,并且长度不超过15位。
经过改造后,新的算法可以支持同一机房内的256台机器34年内生成的ID不重复,并且每台机器每秒可以生成100万个ID,基本可以满足项目组的需要,并且线程安全。
核心代码:
1 | private final long twepoch = 1482192000000L; //twepoch 为System.currentTimeMillis() 方法起始时间1970-1-01 00:00:00.000 到 2017-01-01 00:00:00.000 之间的毫秒数. |
完整代码下载:IdGenerator.java
引用方法非常简单:
1 | System.out.println(IdGenerator.NEXT.uniqueId()); //产生分布式唯一ID |
注意事项
uniqueIdCurDay() 方法中 分布式ID 生成算法 依赖hostId,由于hostId 默认采用IP的第四段,即当应用服务器集群 跨网段部署或者数量超过256台时,可能会导致生成的分布式ID重复。uniqueId() 方法中分布式ID 生成算法依赖hostId和MAC地址对32取余, 所以当应用服务器集群 跨网段部署或者数量超过256台时,生成ID重复的概率要比 uniqueIdCurDay() 方法低很多,但是依然会有重复的可能。
总之,当应用服务器集群 跨网段部署或者数量超过256台时,不建议继续使用该方法生成分布式唯一ID。